
D. Dutta Roy, ISI., Kolkata
For the PG students and fellows of Management
Indian Institute of Management
Shillong
Module-4: Data Analysis-Descriptive (3 Classes)
Data preparation, Data cleaning and missing data; Exploratory data analysis-frequency tables, bar, charts, histograms; Hypothesis testing-Logic to test-types of test-one-sample test, two sample test, Mann-Whitney U test, Kruskal-Wallis test, k-independent sample test
1. WHAT IS BUSINESS RESEARCH METHOD ?
A business research method is a careful and diligent study of a market, an industry or a particular company's business operations, using investigative techniques to discover facts, examine theories or develop an action plan based on discovered facts. It is the systematic and repeated searching process to characterize the operational process of business, its antecedent and consequence.
Here characterization means exploring properties and their relations with specific business operations. So it is objective, time bound and goal directed so that the findings can be used for action research.
Modern business operation follows open system where in feedback is necessary. Feedback from different task agents change operation of the business.
3. WHAT ARE THE TYPES OF BUSINESS RESEARCH METHODS ?
Basic business research methods are :
3.1 Operation Research: A study of a firm's operational systems identifies each production step. In operations research, problems are broken down into basic components and then solved in defined steps by mathematical analysis.This type of business research helps a firm to "reduce waste, inefficiency and poor performance by examining procedures on a step-by-step basis.
3.2 Focus group: Focus groups typically consist of a small group of people consistent with a target market profile that deals with a product or service. Focus groups offer a kind of middle ground between other research methods.
3.3 Case study: This method allows for in-depth information collection, but it is typically time-intensive.
3.4 Interview: This approach typically yields deep information about one person’s experience with a product, service or company.
3.5 Survey: a survey enables researchers to gather large amounts of data quickly and at a comparatively low cost.
3.6 Analysis of secondary data: Financial data like sales, net sales, profit after tax, and many other information of the company are secondary data. Researcher will observe the data and analyze them with visual statistics.
4. WHAT IS DATA PREPARATION ?
Data Preparation involves preparation of database in the computer, data checking, data cleaning, data transformation, missing data.
5. WHAT IS DATA CLEANING ?
It is the process of separating relevant data from irrelevant. It can be made before and after data collection.
6. HOW CAN WE CLEAN THE DATA ?
Before data collection, identify the noise and control them. After data collection, identify the extreme data or outlier using box-whisker plot.
7. HOW DO WE TREAT MISSING DATA ?
7.1 Listwise deletion
7.2 Pairwise deletion (specially for correlation)
7.3 Mean substitution
7.4 Regression substitution
__
8. WHAT IS EXPLORATORY DATA ANALYSIS ?
Exploratory data analysis (EDA) is a technique to identify systematic relations between variables when there are no (or not complete) a priori expectations as to the nature of those relations. In a typical exploratory data analysis process, many variables are taken into account and compared, using a variety of techniques in the search for systematic patterns.
9. WHAT ARE THE TECHNIQUES OF EDA ?
Some basic tools are
9.1 Analysis of single way and multi-way frequency table or cross tabulation
9.2 Analysis of box-whisker plot
Some advanced statistical tools are
9.3 Cluster analysis
9.10 Correspondence analysis
9.11 Principal component analysis
9.14 Discriminant analysis
9.12 Multiple regression analysis
10. WHAT IS HYPOTHESIS TESTING ?
Hypothesis is prior assumption about the results in experiment. Hypothesis testing refers to examining likelihood of the observed and expected result of experiment through statistical tools used for measuring significance like student's t, ANOVA, CHI-SQUARE, correlation etc.
11. HOW CAN WE WRITE HYPOTHESIS ?
There are two types of statistical hypothesis - null and alternative hypotheses. Null hypothesis assumes observed and expected results are same but alternative assumes difference between the two. It is the statement of probability. So use the word 'would' rather is.
Null hypothesis: There would be no significant mean differences in <variable name> between the groups.
Alternative hypothesis: There would be significant mean differences in <variable name> between the groups.
Here significance represents inference to population characteristics or parameter based on sampled data.
12. WHAT IS THE ERROR IN MAKING INFERENCE ?
Making wrong inference about the population based upon results is called error in making difference.
13. WHAT ARE THE TYPES OF ERRORS IN MAKING INFERENCE ?
There are two types of errors in making wrong inference.
Type 1 errors are made when we reject a null hypothesis by marking a difference significant, although no true difference exists.
Type 2 errors are made when we accept a null hypothesis by marking a difference not significant, when a true difference actually exists.
14. WHAT IS REJECTION REGION ?
The rejection region defines the conditions under which the null hypothesis is rejected.
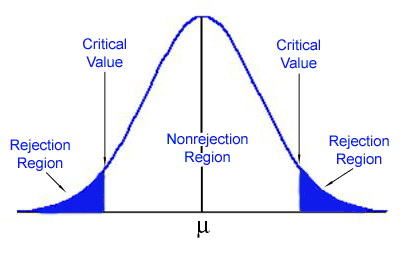
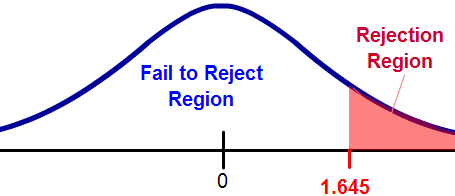
15. WHAT IS ONE-SAMPLE t-TEST ?
The one-sample t-test is used when we want to know whether our sample comes from a particular population but we do not have full population information available to us. For instance, we may want to know if a particular sample of college students is similar to or different from college students in general. The one-sample t-test is used only for tests of the sample mean. Thus, our hypothesis tests whether the average of our sample (M) suggests that our students come from a population with a know mean (m) or whether it comes from a different population. Formula of one sample t-test is given below:
 Ref: http://lap.umd.edu/psyc200/handouts/psyc200_0810.pdf
Ref: http://lap.umd.edu/psyc200/handouts/psyc200_0810.pdf
16. WHAT IS THE DIFFERENCE BETWEEN T-TEST AND Z-TEST ?
Z-TEST / Z-STATISTIC: used to test hypotheses about µ when the population standard deviation is known. And population distribution is normal or sample size is large
T-TEST / T-STATISTIC: used to test hypotheses about µ when the population standard deviation is unknown.
The only difference between the z- and t-tests is that the t-statistic estimates standard error by using the sample standard deviation, while the z-statistic utilizes the population standard deviation
ref: http://lap.umd.edu/psyc200/handouts/psyc200_0810.pdf
17. WHAT IS TWO SAMPLE TEST ?
Two-sample hypothesis testing is statistical analysis designed to test if there is a difference between two means from two different populations.
15.WHAT IS THE FORMULA OF TWO SAMPLE TEST ?

Ref: http://org.elon.edu/econ/sac/twosample.htm
16. WHAT IS CHI-SQUARE TEST ?
Chi-square test represents a useful method of comparing experimentally obtained results with those to be expected theoretically on some hypothesis. Formula of chi-square test is :

where in fo = observed frequency; fe= expected frequency
Assumptions:
17. WHAT IS MANN-WHITNEY U TEST ?
The Mann-Whitney U test is used to compare differences between two independent groups when the dependent variable is either ordinal or continuous, but not normally distributed.
It can be assessed by SPSS. The Mann-Whitney test statistic "U" reflects the
difference between the two rank totals. When dependent measure is continuous, it must be converted into rank. Here lies its difference from t-test.
Learn more from : https://statistics.laerd.com/spss-tutorials/mann-whitney-u-test-using-spss-statistics.php
18. WHAT IS KRUSKAL WALLIS TEST ?
It is called Non-parametric ANOVA. Instead of scores, there will be ranks in each group. Kruskal-Wallis compares between the medians of two or more samples to determine if the samples have come from different populations.
At least 5 data in each group are required for comparison.
19. WHAT IS k-independent sample test ?
k-independent sample test is the non-parametric statistics to compare more than two independent samples. It aims at determining whether the location parameters (medians) of the populations are different.
Example: In one training programs, 90 trainees were randomly assigned into three different programs like competency mapping, personality development and communication skills. After their training, they were invited to the group discussion and each one is assigned score. The goal of analysis is to compare the median scores for the three groups and decide whether different training programs have any effect on the scores.
Sample questions
A. Here is a data set 20, 25, 30, 35,36, 37, 39, 40, 42, 50
(a) Draw stem-leaf plot
(b) Find out location of the mean
B. One assessor ranks 5 machines and one industrial engineer assesses machine performance. Their data are given below
Assessor's ranks : 1,2,3,4,5
Machine performance: 200, 197, 197, 196, 195
Is assessor's rank correct ?
C. Is it true or false ?
BRM is non repetitive research.
9.1 Analysis of single way and multi-way frequency table or cross tabulation
9.2 Analysis of box-whisker plot
Some advanced statistical tools are
9.3 Cluster analysis
9.10 Correspondence analysis
9.11 Principal component analysis
9.14 Discriminant analysis
9.12 Multiple regression analysis
10. WHAT IS HYPOTHESIS TESTING ?
Hypothesis is prior assumption about the results in experiment. Hypothesis testing refers to examining likelihood of the observed and expected result of experiment through statistical tools used for measuring significance like student's t, ANOVA, CHI-SQUARE, correlation etc.
11. HOW CAN WE WRITE HYPOTHESIS ?
There are two types of statistical hypothesis - null and alternative hypotheses. Null hypothesis assumes observed and expected results are same but alternative assumes difference between the two. It is the statement of probability. So use the word 'would' rather is.
Null hypothesis: There would be no significant mean differences in <variable name> between the groups.
Alternative hypothesis: There would be significant mean differences in <variable name> between the groups.
Here significance represents inference to population characteristics or parameter based on sampled data.
12. WHAT IS THE ERROR IN MAKING INFERENCE ?
Making wrong inference about the population based upon results is called error in making difference.
13. WHAT ARE THE TYPES OF ERRORS IN MAKING INFERENCE ?
There are two types of errors in making wrong inference.
Type 1 errors are made when we reject a null hypothesis by marking a difference significant, although no true difference exists.
Type 2 errors are made when we accept a null hypothesis by marking a difference not significant, when a true difference actually exists.
14. WHAT IS REJECTION REGION ?
The rejection region defines the conditions under which the null hypothesis is rejected.
15. WHAT IS ONE-SAMPLE t-TEST ?
The one-sample t-test is used when we want to know whether our sample comes from a particular population but we do not have full population information available to us. For instance, we may want to know if a particular sample of college students is similar to or different from college students in general. The one-sample t-test is used only for tests of the sample mean. Thus, our hypothesis tests whether the average of our sample (M) suggests that our students come from a population with a know mean (m) or whether it comes from a different population. Formula of one sample t-test is given below:
16. WHAT IS THE DIFFERENCE BETWEEN T-TEST AND Z-TEST ?
Z-TEST / Z-STATISTIC: used to test hypotheses about µ when the population standard deviation is known. And population distribution is normal or sample size is large
T-TEST / T-STATISTIC: used to test hypotheses about µ when the population standard deviation is unknown.
The only difference between the z- and t-tests is that the t-statistic estimates standard error by using the sample standard deviation, while the z-statistic utilizes the population standard deviation
ref: http://lap.umd.edu/psyc200/handouts/psyc200_0810.pdf
17. WHAT IS TWO SAMPLE TEST ?
Two-sample hypothesis testing is statistical analysis designed to test if there is a difference between two means from two different populations.
15.WHAT IS THE FORMULA OF TWO SAMPLE TEST ?
Ref: http://org.elon.edu/econ/sac/twosample.htm
16. WHAT IS CHI-SQUARE TEST ?
Chi-square test represents a useful method of comparing experimentally obtained results with those to be expected theoretically on some hypothesis. Formula of chi-square test is :
where in fo = observed frequency; fe= expected frequency
Assumptions:
- Chi-square test follows equal probability hypothesis
- Chi-square is not stable when any experimental frequency is less than 5. Under this condition, Yates correction is computed. 0.5 will be deducted from difference between observed and expected frequency
17. WHAT IS MANN-WHITNEY U TEST ?
The Mann-Whitney U test is used to compare differences between two independent groups when the dependent variable is either ordinal or continuous, but not normally distributed.
It can be assessed by SPSS. The Mann-Whitney test statistic "U" reflects the
difference between the two rank totals. When dependent measure is continuous, it must be converted into rank. Here lies its difference from t-test.
Learn more from : https://statistics.laerd.com/spss-tutorials/mann-whitney-u-test-using-spss-statistics.php
18. WHAT IS KRUSKAL WALLIS TEST ?
It is called Non-parametric ANOVA. Instead of scores, there will be ranks in each group. Kruskal-Wallis compares between the medians of two or more samples to determine if the samples have come from different populations.
At least 5 data in each group are required for comparison.
19. WHAT IS k-independent sample test ?
k-independent sample test is the non-parametric statistics to compare more than two independent samples. It aims at determining whether the location parameters (medians) of the populations are different.
Example: In one training programs, 90 trainees were randomly assigned into three different programs like competency mapping, personality development and communication skills. After their training, they were invited to the group discussion and each one is assigned score. The goal of analysis is to compare the median scores for the three groups and decide whether different training programs have any effect on the scores.
Sample questions
A. Here is a data set 20, 25, 30, 35,36, 37, 39, 40, 42, 50
(a) Draw stem-leaf plot
(b) Find out location of the mean
B. One assessor ranks 5 machines and one industrial engineer assesses machine performance. Their data are given below
Assessor's ranks : 1,2,3,4,5
Machine performance: 200, 197, 197, 196, 195
Is assessor's rank correct ?
C. Is it true or false ?
BRM is non repetitive research.
Thanks for providing such nice information to us. It provides such amazing information the post is really helpful and very much thanks to you Indian Institute of Management shillong
ReplyDelete